
🧙♂️ 想象一下,你有一个魔法笔记本,只要在上面写下任何内容,它就能瞬间记住,而且永远不会忘记。这听起来像是魔法吗?在人工智能的世界里,这种"魔法"正在成为现实。让我们一起揭开这个神奇笔记本的秘密吧!
🔍 揭开神秘面纱:多头注意力机制
在人工智能领域,Transformer模型就像是一个拥有超强记忆力的大脑。它能够处理和记忆大量的信息,无论是长篇文章还是复杂的图像。而这个"大脑"的核心秘密,就藏在一个叫做"多头注意力机制"(Multi-Head Attention, MHA)的结构中。
想象一下,MHA就像是一群专注力超强的学生。每个"学生"(即每个注意力头)都专注于信息的不同方面。有的关注语法,有的注重逻辑,还有的专心记忆关键词。这种多角度的关注,使得MHA能够全方位地理解和记忆信息。
💡 解密记忆魔法:数学视角
那么,这个神奇的记忆机制究竟能记住多少信息呢?研究人员们通过复杂的数学分析,给出了一个令人惊讶的答案。
假设我们有一个拥有$H$个头的注意力机制,每个头的维度是$d$,而且输入序列的长度是$n$。那么,这个机制能够完美记忆的信息量大约是$H \cdot \min(n,d)$。这个公式看似简单,却蕴含着深刻的洞见:
- 增加注意力头的数量($H$)可以线性提升记忆能力。
- 记忆能力受到输入序列长度($n$)和注意力头维度($d$)的共同限制。
这就好比增加"学生"的数量可以提高整体的记忆力,但每个"学生"的能力和要记忆的内容长度也同样重要。
🎭 记忆的艺术:角色分工与协作
研究者们发现,MHA的强大记忆能力不仅来自于简单的数量叠加,更源于其巧妙的"分工协作"机制。
想象一个剧组在排练一部复杂的话剧。每个演员(注意力头)都被分配了特定的角色和台词。有趣的是,当一个演员专注于自己的部分时,其他演员会有意识地"忽略"这部分内容,专注于自己的角色。这种巧妙的分工,确保了整个剧组能够完美地呈现整部话剧,而不会出现重复或遗漏。
在数学上,这种现象被描述为注意力权重的"饱和"。当一个注意力头专注于某些信息时,其对应的softmax权重会接近1,而其他头的权重则接近0。这种机制保证了信息的高效编码,避免了冗余。
🔬 实验验证:理论与现实的碰撞
为了验证这些理论发现,研究人员们设计了一系列精巧的实验。他们使用了不同数量的注意力头、不同的输入序列长度,以及不同的注意力头维度,来测试模型的记忆能力。
实验结果令人振奋:模型的记忆能力确实随着注意力头数量的增加而线性提升。同时,当输入序列长度或注意力头维度达到某个阈值后,继续增加它们并不能带来显著的记忆力提升。这完美印证了理论预测!
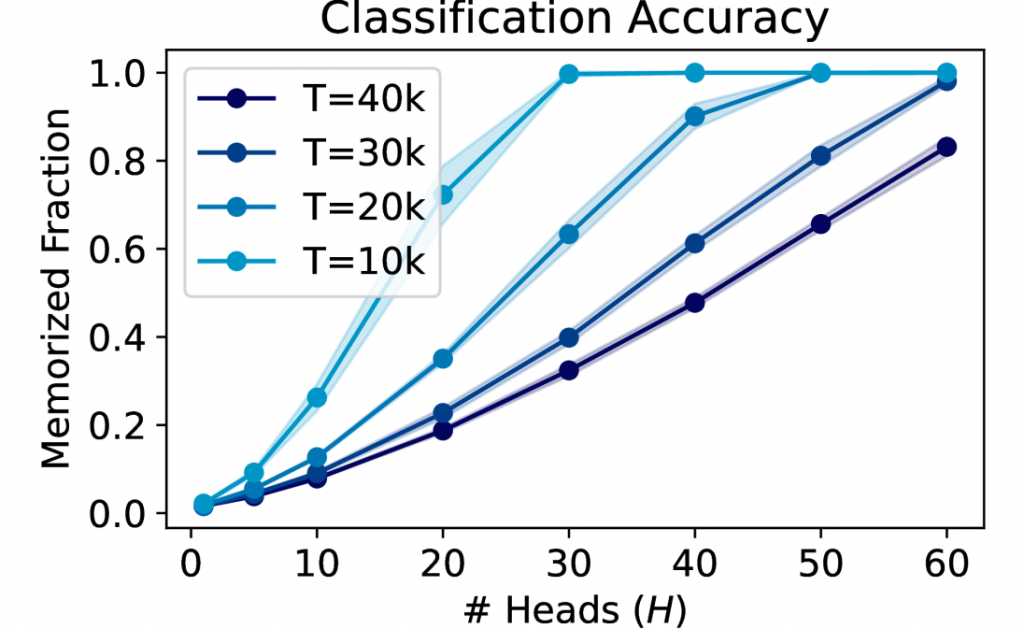
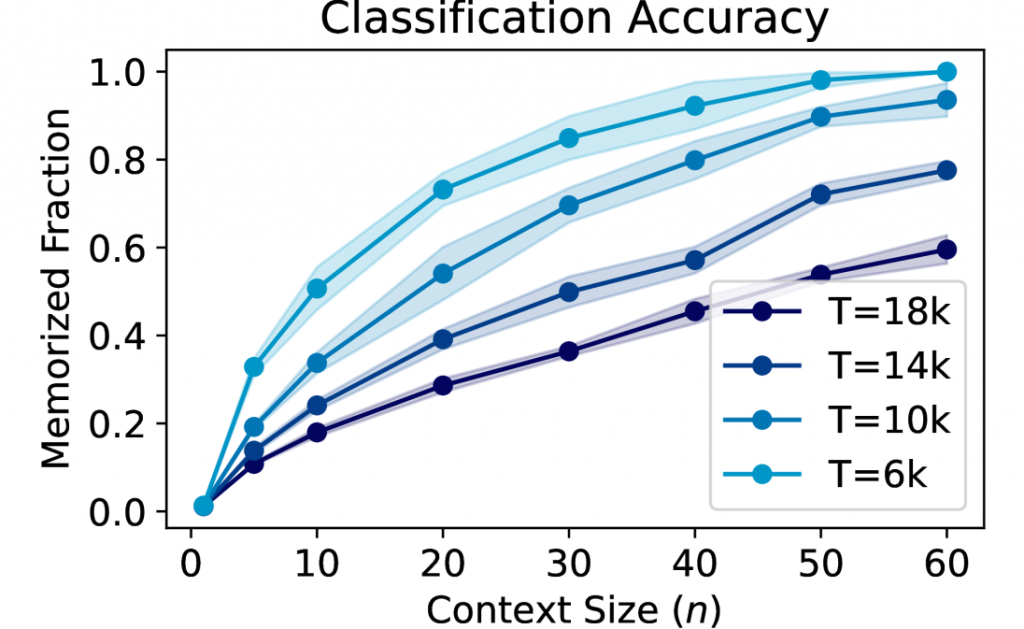
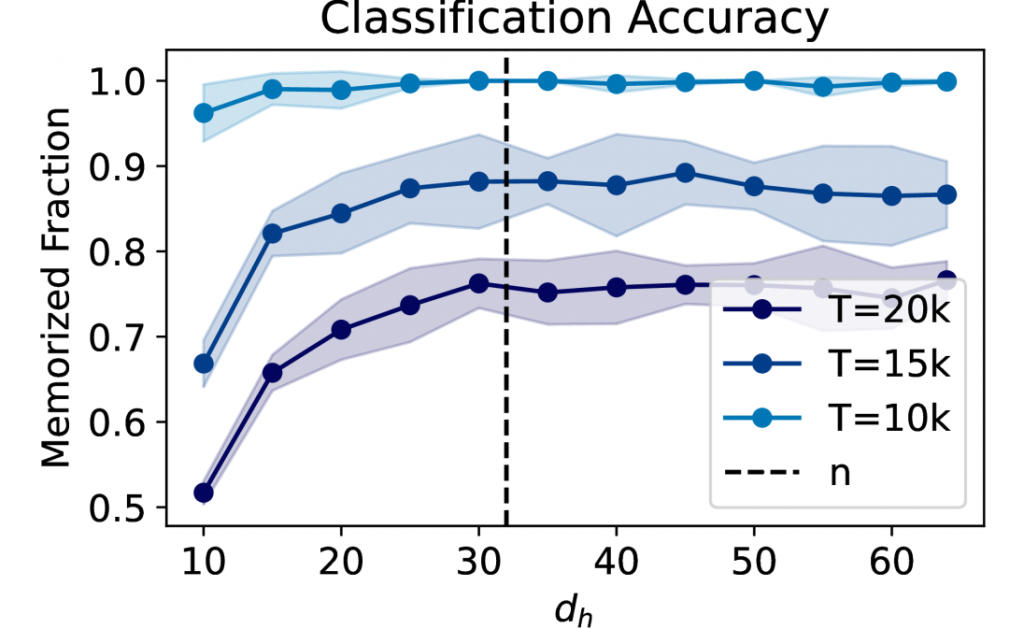
图: 注意力头数量与记忆能力的关系
更有趣的是,研究者们观察到了注意力机制中的"饱和"现象。在成功记忆一组数据后,大多数注意力头都会呈现出高度专注的状态,这与理论预测的"分工协作"机制不谋而合。![饱和现象图][]
图2: 注意力头的饱和现象
🚀 超越极限:与传统模型的对比
研究者们并未止步于此。他们将多头注意力机制与传统的全连接神经网络进行了深入对比。结果显示,在相同参数量的情况下,MHA的记忆能力至少不逊色于传统网络,在某些情况下甚至更胜一筹。
这就像比较一个训练有素的专业记忆团队和一个单打独斗的记忆高手。虽然单个高手可能有惊人的记忆力,但一个协调良好的团队往往能够处理更复杂、更大量的信息。
🌈 未来展望:AI记忆的新篇章
这项研究不仅揭示了多头注意力机制强大记忆能力的秘密,还为人工智能的未来发展指明了方向。
- 模型设计优化: 了解了MHA的记忆机制,研究者们可以更有针对性地设计和优化模型结构,比如合理设置注意力头的数量和维度。
- 隐私与安全: 强大的记忆能力意味着模型可能会记住训练数据中的敏感信息。这提醒我们在AI应用中要更加重视数据隐私和安全问题。
- 认知科学启示: MHA的工作机制在某种程度上模拟了人类的注意力分配和记忆过程。这可能为我们理解人类认知提供新的视角。
- 跨领域应用: 这种高效的记忆机制不仅适用于自然语言处理,还可能在计算机视觉、语音识别等多个领域发挥重要作用。
🎓 结语:解开AI记忆之谜
从神奇的笔记本比喻开始,我们深入探讨了多头注意力机制这个AI世界的"记忆大师"。通过数学分析、形象比喻和实验验证,我们揭示了它强大记忆能力背后的秘密。
这项研究不仅是对Transformer模型核心机制的深入洞察,更是人工智能领域的一个重要里程碑。它让我们离理解和创造真正智能的AI系统又近了一步。
未来,随着研究的深入,我们可能会看到更多基于这些发现的创新应用。也许有一天,我们真的能创造出那个能记住一切的"魔法笔记本"也说不定呢!
参考文献:
- Mahdavi, S. , Liao, R., & Thrampoulidis, C. (2024). Memorization Capacity of Multi-Head Attention in Transformers. arXiv preprint arXiv:2306.02010v3.✅
- Vaswani, A. , Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.✅
- Devlin, J. , Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.✅
- Dosovitskiy, A. , Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., … & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.✅
- Brown, T. , Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.✅