
大家玩梗也玩的差不多了,恰好俺对pdf稍有研究,是时候展示真正的技术了!
我关注的是涂黑效果是如何实现的。
涂黑的定义:从视觉上看不出底层的文字,但是可以通过鼠标划选进行复制。
网上都说是加了一个图层,好吧,这种说法太漂浮,而且「加了一个图层」也不算是PDF的语言。
不想看长篇大论可直接看结论:
1、涂黑时,区域内的文字信息未丢失;
2、使用PDF中名为path的对象实现的涂黑效果;
毛主席老人家教导我们,没有调查就没有发言权,下面就是我的实验过程。
使用的工具:pdftk、pdfinfo、pdfium
step1、找到文档来源
文档的权威来源
https://www.justice.gov/epstein
实验的具体文档:我们采用中间的文档
step2、复现涂黑后能够复制
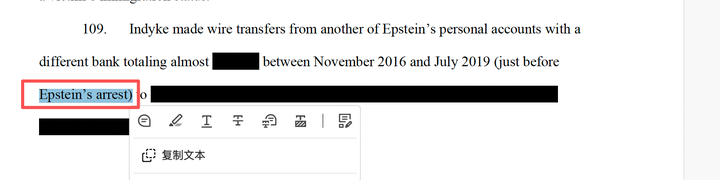
随意翻到涂黑的页面,比如第23页,我们进行复制
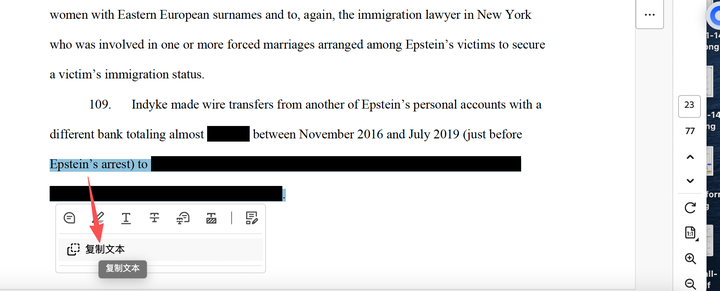
复制的文字如下
Epstein』s arrest) to women with Eastern European surnames, including one known to have
recruited young women and girls for Epstein.
哈哈,若然能够复现!
step3、切分文档,专注某一页
3.1、为什么专注某一页?
因为PDF本身其实非常复杂。我们之所以看PDF时觉得清清爽爽,那是PDF阅读器帮我们读取PDF内容流之后渲染的效果。那PDF本身是什么样的呢?使用文本编辑器打开效果如下:
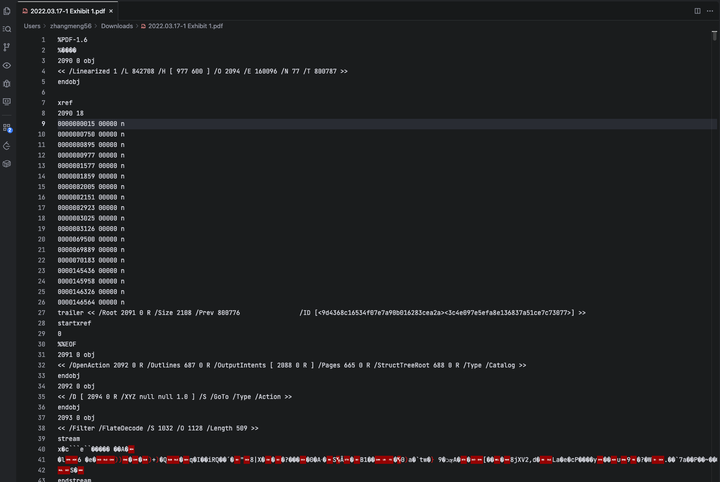
实际上是乱的一批,而且最重要的是,它的内容不是说先放置第一页的内容、然后放置第二页的内容,等等。而是随机的堆积在一起,它是通过各个索引联系起来的树状结构。
所以为了降低我们的研究难度,我们只关注具体某一页,比如第23页。
3.2、使用工具切分23页得到单独的PDF
我们这里使用pdftk工具,具体执行如下:
pdftk 2022.03.17-1\ Exhibit\ 1.pdf cat 23-23 output black_can_copy.pdf我们得到了一个新的PDF文档,它只有一页,由 2022.03.17-1 Exhibit 1.pdf 的第23页组成。
step4、具体研究某一页
4.1、PDF简单介绍
PDF实际可以认为是一种基于坐标描述的矢量页面描述语言。它包含的所有元素,比如text、path、img其实都需要指定坐标。
比如对于path来说,一般来说它的绘制指令可能就是从坐标(x1, y1)开始,到坐标(x2, y2)结束,画一条宽度=2的黑色直线。
上面的绘制指令用PDF的语言来说,大致可以写成
2 w % 设置线宽 (line width) 为 2
0 0 0 RG % 设置描边颜色为黑色 (DeviceRGB,0 0 0 为黑)
0 0 0 rg % 设置填充颜色为黑色 (可选,通常描边即可)
x1 y1 m % 移动到起点 (move to)
x2 y2 l % 绘制直线段到终点 (line to)除了上面那种path的画法,还有一种,指定起始点(x, y) ,然后规定宽度w和高度h,可以画一个矩形
x y % 起始点坐标
w % 宽度
h % 高度
re % 画一个矩形写到这里,我觉得最重要的问题就是:坐标坐标,肯定要有原点呐。PDF中坐标原点是左下角。
4.2、解压pdf文档
我们搜索涂黑附近的文字——Epstein
但是我们居然找不到!
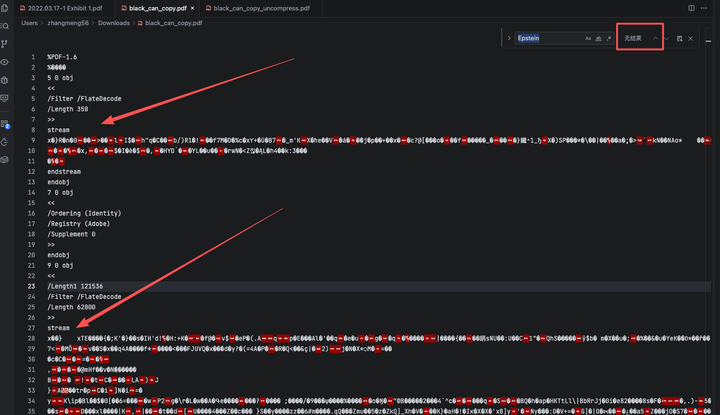
这是可能的,注意看图中红色箭头所指的 stream 字段,它是乱码的。这是因为PDF对很多元素,比如text、img进行了压缩,我们需要通过解压来获取真实的内容。
我们使用pdftk工具
pdftk black_can_copy.pdf output black_can_copy_uncompress.pdf uncompress我们重新生成了内容解压之后的文档,让我们继续查查看
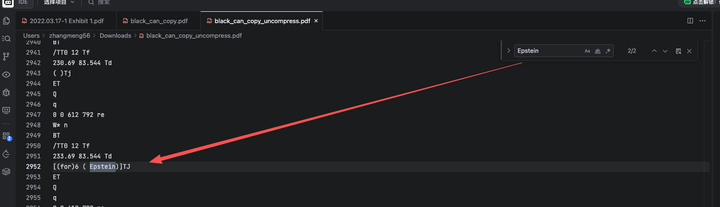
找到了,并且坐标是(233.69, 83.544)
不如让我们直接找一下涂黑部分的文字,我们从一开始就知道,涂黑部分文字如下:
Epstein』s arrest) to women with Eastern European surnames, including one known to have
recruited young women and girls for Epstein.
哦,对上了!
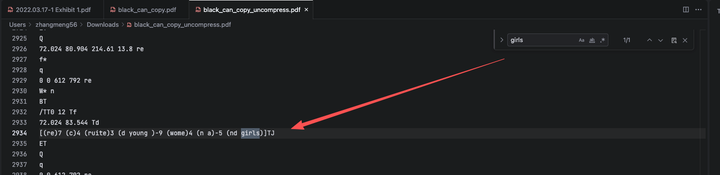
也就是说,不论涂黑这个效果是如何实现的,它所在区域的文字依然存在。所以哪怕不能通过鼠标划选进行复制,我们也一定能够通过眼睛看、程序解析的形式获取到文字信息。
4.3、涂黑效果是如何实现的
像这种方方正正的path,一般都是通过re命令进行绘制的,我们在文档中通过关键字re进行查找
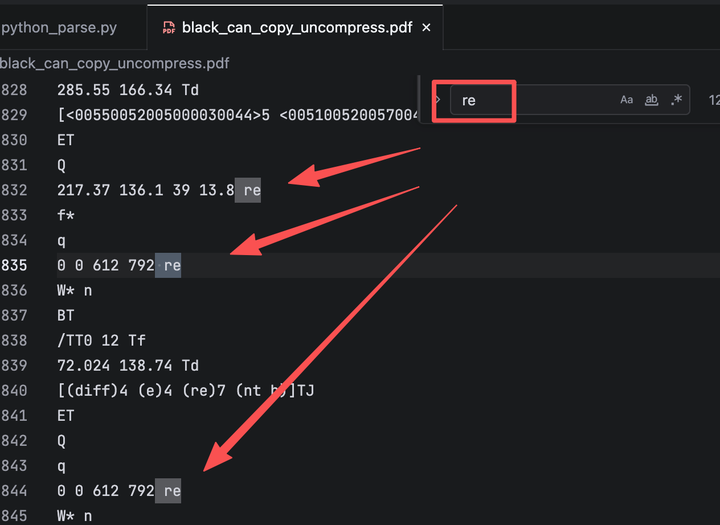
0 0 612 792 re
0 0 612 792 re
0 0 612 792 re
0 0 612 792 re
0 0 612 792 re
0 0 612 792 re
......
0 0 612 792 re
217.37 136.1 39 13.8 re
165.62 108.5 341.14 13.8 re
72.024 80.904 214.61 13.8 re我们应该找到了, 0 0 612 792 re 看数据指的使整个页面,他虽然画整个页面,但是可能不填充,对我们视觉上没有影响。
我们可以仔细观察最后三个re,拿第一个为例
217.37 136.1 39 13.8 re
定义一个矩形路径,左下角坐标(217.37, 136.1),宽度39,高度13.8最后三个re的宽度分别为:39、241.14、341.14,从肉眼上观察,差不多正好图中的三个涂黑区域的长度。我们可以测量一下:

第二长的长度:17.5-11.1=6.4

第一长的长度:24.2-13.9=10.3
已知 $\frac{214.61}{341.14}=0.6290$ , $\frac{6.4}{10.3}=0.6213$
基本可以认定,我们就是找到了涂黑区域了。它就是通过path的做法进行涂黑的。
上面通过层层剥丝抽茧,我们最终得知涂黑是通过添加Path这种类型的东西,其实还有一种更加快捷的方法,那就是使用福昕高级PDF编辑器,查看文档元素内容:

那为什么我们不从一开始就使用福昕编辑器呢?
是因为我想通过探究涂黑的过程科普一下PDF这种文档结构(其实是行文至此,我才想起来福昕高级PDF编辑器,免费给你打广告了,给我打钱,谢谢)
4.4、补充知识:确定旋转角度
PDF中坐标原点一定是左下角,但是PDF允许页面进行旋转,此时它的坐标原点相对于PDF阅读器展现出来的左下角,肯定是要做相应调整的。不过在这个例子中,我们可以不予考虑,因为这一页没有旋转角度,是一个「正常」的页面。
如何确定该页没有旋转呢?
我们使用pdfinfo工具,重点关注 rot字段值。这里为0表示不进行旋转。
pdfinfo black_can_copy.pdf -f 1 -l 1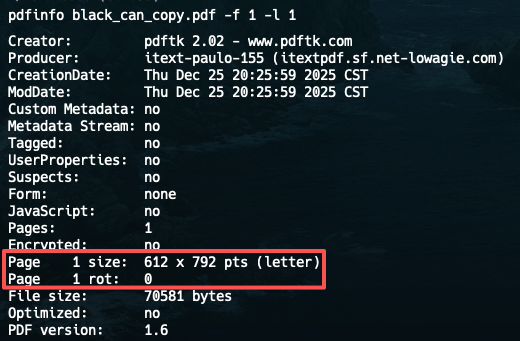
总结
美国政府公布的爱泼斯坦案件相关PDF的涂黑加密是通过添加PDF世界中的path对象。这里给出PDF元素类型的枚举值
const (
FPDF_PAGEOBJ_TEXT FPDF_PAGEOBJ = 1
FPDF_PAGEOBJ_PATH FPDF_PAGEOBJ = 2
FPDF_PAGEOBJ_IMAGE FPDF_PAGEOBJ = 3
FPDF_PAGEOBJ_SHADING FPDF_PAGEOBJ = 4
FPDF_PAGEOBJ_FORM FPDF_PAGEOBJ = 5
)类型3PDF世界中的图片类型,所以严格来说,涂黑并不是网上说的那种「只是添加了一个图层」,虽然差不多是那个意思咯~
展望1、修改涂黑效果
去掉涂黑path
效果如图所示

代码如下
将涂黑变色
效果如图所示



代码如下
咦,你说看不到代码?哈哈,v我50,开玩笑,是我觉得没必要,会让篇幅变得很长~
展望2、实现一个「真加密」涂黑
我想到了两种不同的方案,不过这里的地方太小写不下,下次一定~