教会大语言模型表达自信:自我反思性解释的应用



This paper introduces SaySelf, a novel …

大型语言模型 (LLM) 如 Llama,凭借其强大…

在训练语言模型 (如 LLaMA) 时,损失函数 (…

近期,美国经济数据释放出令人担忧的信号…

引言 在人工智能的世界里,语言模型 (LLMs…

引言:语言模型的新突破 在人工智能领域,…

你是否留意过自家路由器的 WAN 口 IP 地址?最…

随着智能手机的普及和使用时间的增加,人…
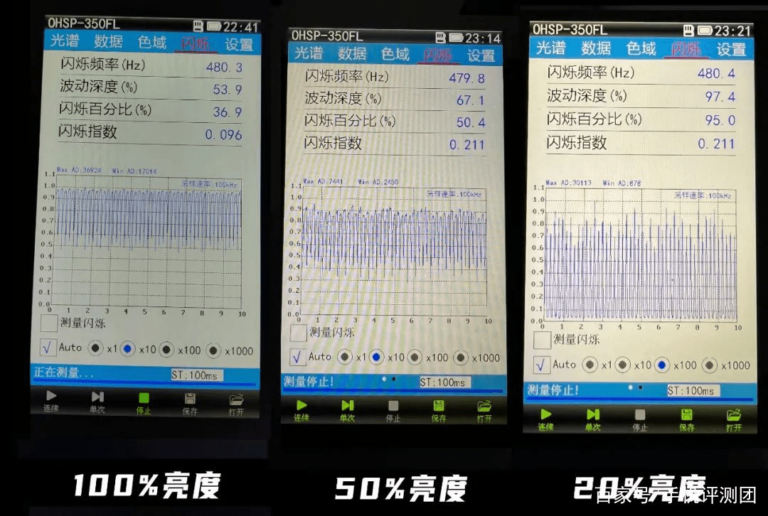
随着智能手机的普及和使用时间的增加,人…

一、什么是 SSE? Server-Sent Events (SS…

苹果公司最近在人工智能领域取得了新的研…