[1] Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y., Lebron, F., Sanghai, S.: GQA: Training generalized multi-query transformer models from multi-head checkpoints. In: Bouamor, H., Pino, J., Bali, K. (eds.) Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 4895–4901. Association for Computational Linguistics, Singapore (Dec 2023). https://doi.org/10.18653/v1/2023.emnlp-main.298, https://aclanthology.org/2023.emnlp-main.298 … [30] Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision-language understanding with advanced large language models. CoRR abs/2304.10592 (2023). https://doi.org/10.48550/ARXIV.2304.10592
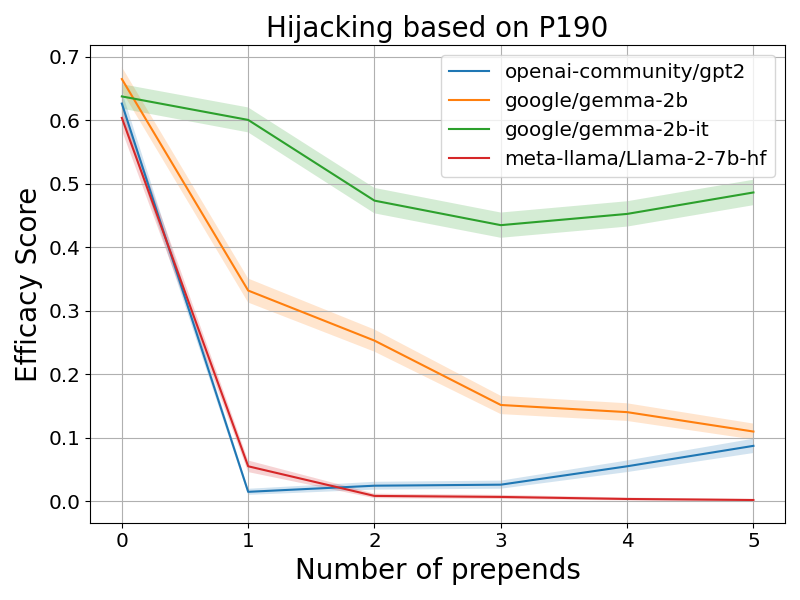
第二种方案是利用关系 ID r 来添加事实上正确的句子。例如,可以将上面的例子劫持为“埃菲尔铁塔不在关岛。埃菲尔铁塔在…”。图 2(b) 报告了基于关系 ID P190(“姐妹城市”)的劫持结果。我们可以看到类似的模式,即添加的句子越多,ES 分数越低。值得注意的是,即使只包含与错误目标语义相近的词(例如,对于错误目标“法语”,使用“法国”),也可以进行劫持。这表明上下文劫持不仅仅是 LLM 从上下文中复制标记。
本文提出了一个合成预测任务,其中对于每个输出标记 y,上下文中的标记(用 x 表示)从给定 y 的条件分布中采样。与 y 相似的标记将更容易出现在上下文中,但 y 本身除外。潜在概念关联的任务是在给定 p(x|y) 的样本的情况下成功检索标记 y。这种合成设置简化了语言的顺序性,这一选择得到了先前关于上下文劫持实验的支持(第 3 节)。
为了衡量相似性,本文定义了一个潜在空间。潜在空间是 m 个二元潜在变量 Zi 的集合,可以将其视为语义概念变量。令 Z = (Z1, …, Zm) 为对应的随机向量,z 为其具体值,𝒵 为所有潜在二元向量的集合。对于每个潜在向量 z,都有一个关联的标记 t ∈ [V] = {0, …, V-1},其中 V 是标记的总数。这里我们用 ι 表示标记器,其中 ι(z) = t。在本文中,我们假设 ι 是标准标记器,其中每个二元向量映射到其十进制数。换句话说,潜在向量和标记之间存在一一映射。由于映射是一对一的,我们有时会交替使用潜在向量和标记。我们还假设每个潜在二元向量都有一个唯一的对应标记,因此 V = 2^m。
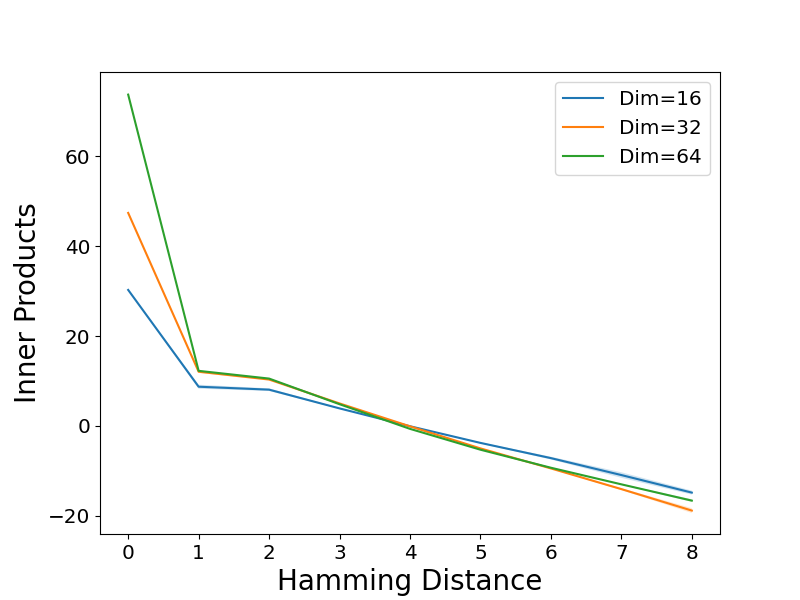
⟨W_E(t), W_E(t')⟩ = { b_0 t = t',
-a DH(t, t') + b t ≠ t'
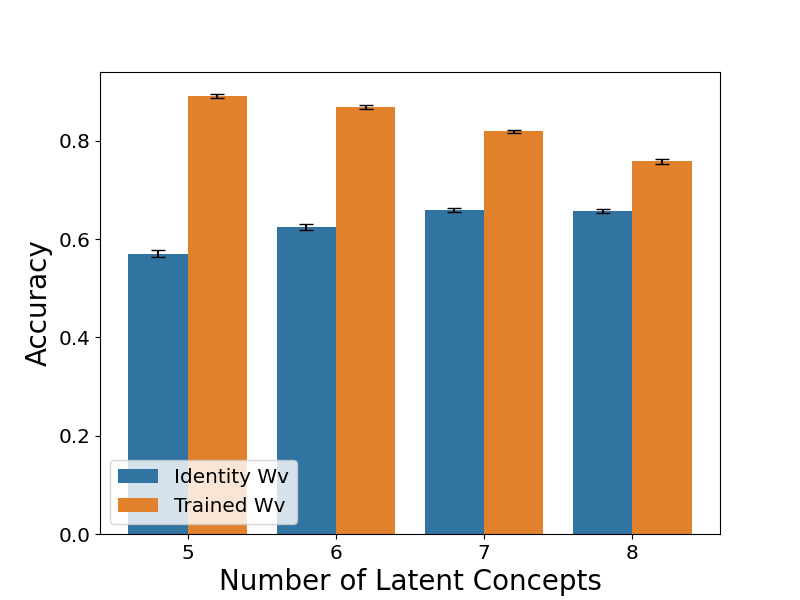
对于任意两个标记 t 和 t’,其中 b_0 > b 且 a > 0。可以将其视为高斯初始化下的嵌入几何结构与 W_V 为单位矩阵时的几何结构的组合(定理 3)。重要的是,这种结构表明训练好的嵌入本身就捕获了潜在空间内的相似性。从理论上讲,这种嵌入结构(公式 5.2)在 b_0、b 和 a 的特定条件下也可以导致低错误率,这由以下定理阐明。
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
Meng, K., Bau, D., Andonian, A., and Belinkov, Y. (2022). Locating and editing factual associations in gpt. Advances in Neural Information Processing Systems, 35:17365–17380.
Meng, K., Lee, D., Bau, D., and Belinkov, Y. (2023). Mass-editing factual associations in language models. arXiv preprint arXiv:2303.08354.
De, A., Burns, C., Malinowski, M., and Rumshisky, A. (2021). Editing factual knowledge in language models. arXiv preprint arXiv:2112.08155.
Mitchell, E., Lin, C.-J., Bosselut, A., Finn, C., and Manning, C. D. (2021). Fast model editing at scale. arXiv preprint arXiv:2110.11309.
Mitchell, E., Lee, K., Khabsa, M., Lin, C.-J., Finn, C., and Manning, C. D. (2022). Memory-based model editing at scale. arXiv preprint arXiv:2207.14296.
Dai, D., Dong, L., Hao, Y., Sui, Z., Ke, F., Zhang, J., Zhang, Y., Wang, J., and Qiu, X. (2021). Knowledge neurons in pretrained transformers. arXiv preprint arXiv:2104.08688.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
Team, G. (2024). Gemma.
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. (2023). Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
Zhao, W., Peng, B., Zhou, C., Wang, J., and Chang, S. (2023). Context-aware prompt learning for few-shot text classification. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6436–6448.
Firth, J. R. (1957). A synopsis of linguistic theory, 1930–1955. Studies in linguistic analysis.
Li, Z., Wallace, E., Shen, S., Lin, K., Ke, G., and Zhang, S. (2023). Transformers learn in-context by gradient descent. arXiv preprint arXiv:2308.12175.
Tarzanagh, D. A. and Dasgupta, S. (2023). Margin maximization in transformers for in-context few-shot learning. arXiv preprint arXiv:2305.11146.
Li, Z., Wallace, E., Shen, S., Lin, K., Ke, G., and Zhang, S. (2024). The mechanics of in-context learning in transformers. arXiv preprint arXiv:2401.04182.
Cover, T. M. (1999). Elements of information theory. John Wiley & Sons.
Devroye, L., Lugosi, G., and Boucheron, S. (2013). A probabilistic theory of pattern recognition, volume 31. Springer Science & Business Media.
Loshchilov, I. and Hutter, F. (2017). Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
自从Transformer被引入以来(Vaswani et al., 2017),衍生的大型语言模型(LLMs)在多个自然语言处理(NLP)任务上不断提升了技术水平。其中,开放域对话是指设计一个对话代理,使其能够在任何话题上与用户进行社交互动,展示出人类的能力,如共情、个性和娱乐性(Walker et al., 2021)。常见的方法是使用特定的数据集进行微调,通常针对某一或多种技能(例如PersonaChat,Blended Skill Talk,Empathetic Dialogues等)。然而,这些数据集的构建成本高且通常仅限于一种语言。
Andreas, J. (2019). Measuring compositionality in representation learning.
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2001). Latent Dirichlet allocation.
Bolukbasi, T., Chang, K.-W., Zou, J. Y., Saligrama, V., & Kalai, A. T. (2016). Man is to computer programmer as woman is to homemaker? debiasing word embeddings.
Bricken, A., Liang, P., & Gilpin, L. H. (2023). Dictionary learning with transformers for interpretable image classification.
Chen, T. Q., Li, X., Grosse, R. B., & Duvenaud, D. K. (2020). Isolating sources of disentanglement in variational autoencoders.
Espinosa Zarlenga, J. M., Cogswell, M., Goh, H., & Romero, A. (2022). Improving robustness and calibration in medical imaging with semantic-aware contrastive learning.
Fel, T., Bau, D., & Regev, I. (2023). Craft: Concept-driven representation learning by adaptive feature transformation.
Frankland, S. J., & Greene, M. R. (2020). Generative models of visual imagination.
Ghorbani, A., Abid, A., Zhu, J., Liu, C., Huang, X., & Schuetz, A. (2019). Towards automatic concept-based explanations.
Havaldar, P., Stein, A., & Naik, M. (2023). Explaining by aligning: Interpreting decisions by aligning model behavior across groups.
Higgins, I., Matthey, L., Pal, A., Burgess, C., Glorot, X., Botvinick, M., … & Lerchner, A. (2016). Beta-vae: Learning basic visual concepts with a constrained variational framework.
Hill, F., Cho, K., & Korhonen, A. (2018). Learning distributed representations of sentences from unlabelled data.
Johnson, J., Hariharan, B., van der Maaten, L., Fei-Fei, L., Lawrence Zitnick, C., & Girshick, R. (2017). Clevr: A diagnostic dataset for compositional language and elementary visual reasoning.
Kim, B., Wattenberg, M., Gilmer, J., Cai, C., Wexler, J., Viegas, F., & Sayres, R. (2018). Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav).
Koh, P. W., Nguyen, T., Tang, Y. S., Wang, S., Pierson, E., Kim, B., … & Liang, P. (2020). Concept bottleneck models.
Kwon, Y., Kim, S., & Yoon, J. (2023). Editing compositional transformations in latent space.
Lake, B. M. (2014). Concept learning in humans and machines: Fundamental issues and a possible solution.
Lewis, H., Purdy, W., & Steinhardt, J. (2022). Transformers learn in-context compositionality.
Lovering, J., & Pavlick, E. (2022). Relational probes: A technique for analyzing the compositional capabilities of language models.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Efficient estimation of word representations in vector space.
Mitchell, T. (1999). Machine learning and data mining.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021). Learning transferable visual models from natural language supervision.
Rigotti, M., Spooner, T., Dodge, J., Gould, S., & Gordon, G. J. (2022). Learning to explain by concept discovery.
Rousseeuw, P. J. (1987). Silhouettes: A graphical aid to the interpretation and validation of cluster analysis.
Santurkar, S., Friedman, C., Wallace, E., Kulkarni, A., Zeng, A., & Thorat, A. (2021). Editing memories: Towards controllable and safe generation with transformers.
Schaeffer, R., Wang, S., Huang, D., Dhingra, B., Sanchez-Lengeling, B., Blunsom, P., & Cohen, W. W. (2024). Beyond language: Towards a unified foundation model evaluation benchmark.
Srivastava, A., Mittal, A., Thiebaut, J., Yen-Chun Chen, T., Manjunath, A., Jain, A., … & Salakhutdinov, R. (2023). Beyond the imitation game: Quantifying and extrapolating capabilities of language models.
Stein, A., Havaldar, P., & Naik, M. (2023). Towards group-fair concept-based explanations.
Tamkin, A., Brundage, M., Clark, J., & Amodei, D. (2023). Understanding the capabilities, limitations, and societal impact of large language models.
Todd, S., Srivastava, S., Htut, P. M., & Chang, M. W. (2023). Discovering latent knowledge in language models without supervision.
Todd, S., Srivastava, S., Htut, P. M., & Chang, M. W. (2024). Probing for robust, factual knowledge in language models.
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., … & Lample, G. (2023). Llama 2: Open foundation and fine-tuned chat models.
Trager, M., Elhage, A., Bharadwaj, S., Kenton, Z., Bhatia, N. S., Cobb, A., … & Amodei, D. (2023). Linear algebra audits: Explaining and controlling language model behavior.
Tschandl, P., Rosendahl, C., & Kittler, H. (2018). The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions.
Turpin, M., Khandelwal, U., Roberts, A., Lee, J., Raffel, C., Shazeer, N., & Irwin, J. (2024). Foundation models for decision-making: Problems, opportunities, and risks.
Wah, C., Branson, S., Welinder, P., Perona, P., & Belongie, S. (2011). The Caltech-UCSD Birds-200-2011 dataset.
Wang, C., Locatello, F., Schmidhuber, J., & Lapedriza, A. (2022). Pivron: Privacy-preserving representation learning with variational inference.
Wang, Z., Xie, Y., Wang, X., Zhou, W., Yu, S., Sun, S., … & Zhou, J. (2023). Compositional visual reasoning with large language models.
Wong, E., Schmidt, L., Torralba, A., & Jegelka, S. (2021). Discovering concepts for realistic counterfactual explanations.
Wu, Y., Wang, X., Tan, C., Huang, D., Wei, F., Zhou, M., … & Zhou, J. (2023). Reasoning with heterogeneous knowledge: Uncovering emergent reasoning abilities of large language models in e-commerce.
Xu, Y., Zhao, S., Song, J., Zhao, H., Eskenazi, M., LeCun, Y., & Romero, A. (2022). How well do vision transformers learn inductive biases? a case study in object recognition.
Yang, J., Wang, S., Zhou, D., Liu, M., Chang, P.-Y., & Zhao, W. X. (2023). Conceptgraph: Mining concept knowledge graph from pretrained language models for interpretable logical reasoning.
Yeh, C.-K., Hsieh, C.-Y., Suggala, A., Ravikumar, P., & Kumar, P. (2020). On textembeddings for numerical features.
Yuksekgonul, M., Gokmen, S., Elhoseiny, M., & Cicek, O. (2023). Zero-shot concept recognition for robot manipulation with large language models.
Yun, S., Oh, S. J., Bastani, O., & Lee, K. (2021). Transformers provide surprisingly effective representations for online and offline dictionary learning.
Zhai, C. (1997). Exploiting context to identify ambiguous terms.
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., & Torralba, A. (2018). Learning deep features for discriminative localization.
Zou, Y., Wang, L., Hu, Z., Li, Z., Wang, W., Tu, Z., … & Sun, M. (2023a). Controllable generation from pre-trained language models via inverse prompting.
Zou, Y., Wang, L., Hu, Z., Li, Z., Wang, W., Tu, Z., … & Sun, M. (2023b). Controllable generation from pre-trained language models via inverse prompting.
近年来,Transformer 模型在自然语言处理等领域取得了巨大成功。与此同时,结构化状态空间模型(SSM)作为一种新兴的序列建模方法也展现出了强大的潜力。最近的研究表明,这两类看似截然不同的模型其实存在着深层次的联系。本文将介绍一项重要的理论突破 – State Space Duality(SSD)框架,该框架揭示了Transformer和SSM之间的对偶性,为统一和改进这两类模型提供了新的视角。
The Polyfill.js project, a popular open-source library used to support older browsers, has been compromised by a supply chain attack. The attack occurred after a Chinese company acquired the ownership of the polyfill.io domain [1]. As a result, more than 100,000 websites that embed the cdn.polyfill.io domain have been affected [2].
Details of the attack:
The new Chinese owner of the Polyfill.js project injected malware into the polyfill.io domain, which is used by numerous websites [2].
The malware is dynamically generated based on HTTP headers, allowing for multiple attack vectors [2].
The injected code redirects mobile users to a sports betting site using a fake Google Analytics domain [2].
The malware has specific protections against reverse engineering and only activates on specific mobile devices at specific hours. It also avoids activating when it detects an admin user and delays execution when a web analytics service is found [2].
Impact and recommendations:
Users of websites that embed the cdn.polyfill.io domain may be unknowingly redirected to malicious sites, such as sports betting and adult content websites [2].
The original creator of the Polyfill.js project recommends not using Polyfill at all, as modern browsers no longer require it [2].
Trustworthy alternatives to Polyfill, provided by Fastly and Cloudflare, are available for those who still require similar functionality [2].
Google has started sending warnings about loading third-party JavaScript from domains like polyfill.io to protect users from potential harm [3].