在人工智能的浩瀚星空中,Transformer模型犹如一颗璀璨的北极星,照亮了计算机视觉和自然语言处理的前进道路。然而,就像每一个超级英雄都有自己的弱点一样,Transformer也面临着一个不小的挑战:当任务涉及长序列处理时,它的计算复杂度会呈现二次方增长,就像是超人遇到了氪石。这个问题在高分辨率图像生成等任务中尤为突出,仿佛是给超人套上了一件沉重的铠甲,让他举步维艰。
但是,别担心!科技的进步从不停歇。今天,让我们一起来认识一位新晋的AI明星:Diffusion-RWKV。它就像是Transformer的改良版,不仅继承了前辈的优秀基因,还进行了一系列的"基因编辑",使其更适合于图像生成的特殊需求。
🎨 Diffusion-RWKV:AI艺术家的神奇画笔
想象一下,如果让AI来画一幅画,会是什么样的场景?传统的方法可能就像是用一支笔从左到右,从上到下一点点地填充画布。而Diffusion-RWKV则更像是一位天才画家,他先在脑海中构思整体布局,然后用魔法般的笔触,让整幅画作同时在各个区域逐步显现出来。
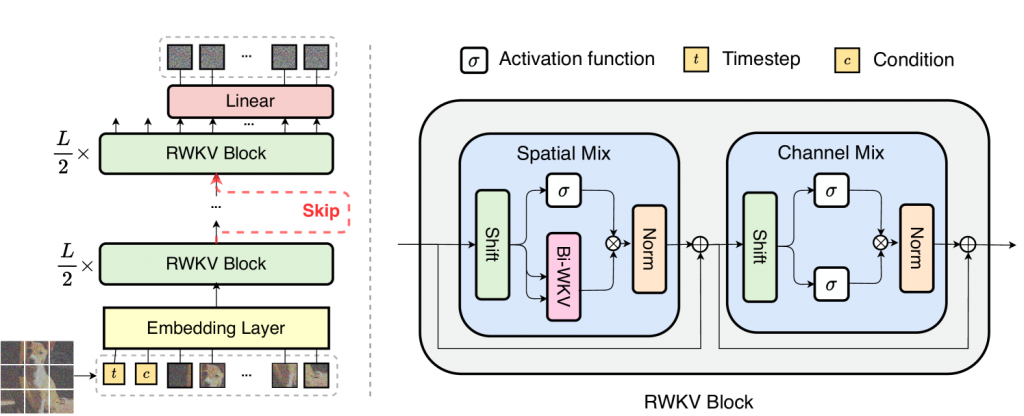
Diffusion-RWKV的核心魔法来自于它的双向RWKV块(Bi-directional RWKV block)。这个结构就像是画家的左右手,可以同时在画布的不同位置作画,既能关注局部细节,又能把控整体风格。这种双向处理的能力,让Diffusion-RWKV在处理高分辨率图像时如鱼得水,不需要像其他模型那样把画布分割成小块逐一处理。
🔍 深入解析:Diffusion-RWKV的秘密武器
- 图像分块(Image tokenization):
想象你要描述一幅复杂的画作,你会怎么做?可能会先把画分成几个主要部分,然后再逐一描述。Diffusion-RWKV就是采用类似的策略,它先将输入的图像划分成一个个小方块(patch),每个小方块就像是一个词语,组合起来就构成了整幅图像的"句子"。 - 双向RWKV块(Bi-directional RWKV block):
这是Diffusion-RWKV的核心创新。传统的RWKV只能单向处理信息,就像是只能从左到右读一本书。而双向RWKV块则可以同时从两个方向处理信息,就像是可以同时从书的开头和结尾开始阅读,然后在中间汇合。这种双向处理能力大大提高了模型捕捉图像全局信息的能力。 - 跳跃连接(Skip connection):
在深度学习中,信息在网络深处传递时可能会逐渐减弱,就像是打电话时声音越传越远越模糊。跳跃连接就像是在网络中架设了一些"直通电话",让浅层的信息可以直接传递到深层,保证了信息的完整性。 - 线性解码器(Linear decoder):
当模型完成了对图像的处理后,需要将结果转换回我们肉眼可见的图像。线性解码器就承担了这个角色,它就像是一位翻译官,将AI的"语言"翻译成人类可以理解的图像。 - 条件融合(Condition incorporation):
如果我们想让AI画一只特定的猫,或者一朵特定颜色的花,就需要给模型一些额外的信息或指令。条件融合就是将这些额外信息巧妙地融入到模型的处理过程中,就像是给画家一些具体的创作指导。
🚀 性能分析:Diffusion-RWKV的超能力
在实验中,Diffusion-RWKV展现出了令人瞩目的表现。无论是在无条件图像生成还是类别条件图像生成任务中,它都能与现有的CNN或Transformer基础的扩散模型相媲美,甚至在某些方面更胜一筹。
特别值得一提的是,Diffusion-RWKV在处理高分辨率图像时表现出色。当图像分辨率从256×256提升到512×512时,Diffusion-RWKV的优势更加明显。它不仅能保持图像质量,还能显著减少计算量,这就像是一位能在巨幅画布上创作精细画作,却不需要耗费太多时间和精力的超级画家。
🎭 案例研究:Diffusion-RWKV的艺术展
让我们来欣赏一下Diffusion-RWKV的"作品"。在ImageNet数据集上训练的模型能够生成各种逼真的图像,从可爱的动物到复杂的场景,每一幅都栩栩如生。特别是在512×512的高分辨率下,图像的细节更加丰富,纹理更加清晰,仿佛能透过屏幕感受到画面中的生命力。

🌈 结论与展望:AI艺术的新纪元
Diffusion-RWKV的出现,无疑为AI图像生成领域带来了一股新的力量。它不仅继承了RWKV在处理长序列时的高效性,还通过巧妙的设计,使其更适合于图像生成任务。这种模型不仅在性能上可以与现有的顶尖模型相媲美,还在计算效率上有明显优势,特别是在处理高分辨率图像时。
未来,我们可以期待看到更多基于Diffusion-RWKV的应用,也许是更高分辨率的图像生成,或者是实时的视频创作。随着模型的进一步优化和硬件的不断进步,AI艺术创作的边界将不断被推进,为我们带来更多惊喜和创新。
Diffusion-RWKV的成功,也为我们提供了一个重要的启示:在AI领域,创新往往来自于对现有技术的巧妙组合和改进。通过将RWKV的高效性与扩散模型的生成能力相结合,研究人员创造出了一个既强大又高效的新模型。这种跨领域的思维碰撞,将继续推动AI技术的发展,为我们开启更多可能性。
让我们共同期待,在不久的将来,Diffusion-RWKV这位AI艺术家能为我们带来更多令人惊叹的作品,让科技与艺术的边界变得更加模糊,创造出更多让人眼前一亮的奇迹。
参考文献:
- Vaswani, A. , et al. (2017). Attention is all you need. Advances in neural information processing systems, 30.✅
- Ho, J. , et al. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems, 33, 6840-6851.✅
- Peng, B. , et al. (2023). RWKV: Reinventing RNNs for the transformer era. arXiv preprint arXiv:2305.13048.✅
- Lin, Z. , et al. (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv preprint arXiv:2312.00752.✅
- Fei, Z. , et al. (2024). Diffusion-RWKV: Scaling RWKV-Like Architectures for Diffusion Models. arXiv preprint arXiv:2404.04478v1.✅