创建型设计模式详解:通俗易懂的例子

在软件设计中,创建型设计模式帮助我们在…

在软件设计中,创建型设计模式帮助我们在…

接口分离原则 (Interface Segregation Pri…

最高人民法院于 2024 年 8 月 27 日正式发布 《关…

在面向对象设计中,依赖倒置原则 (Depende…

在面向对象设计中,里氏替换原则 (Liskov …
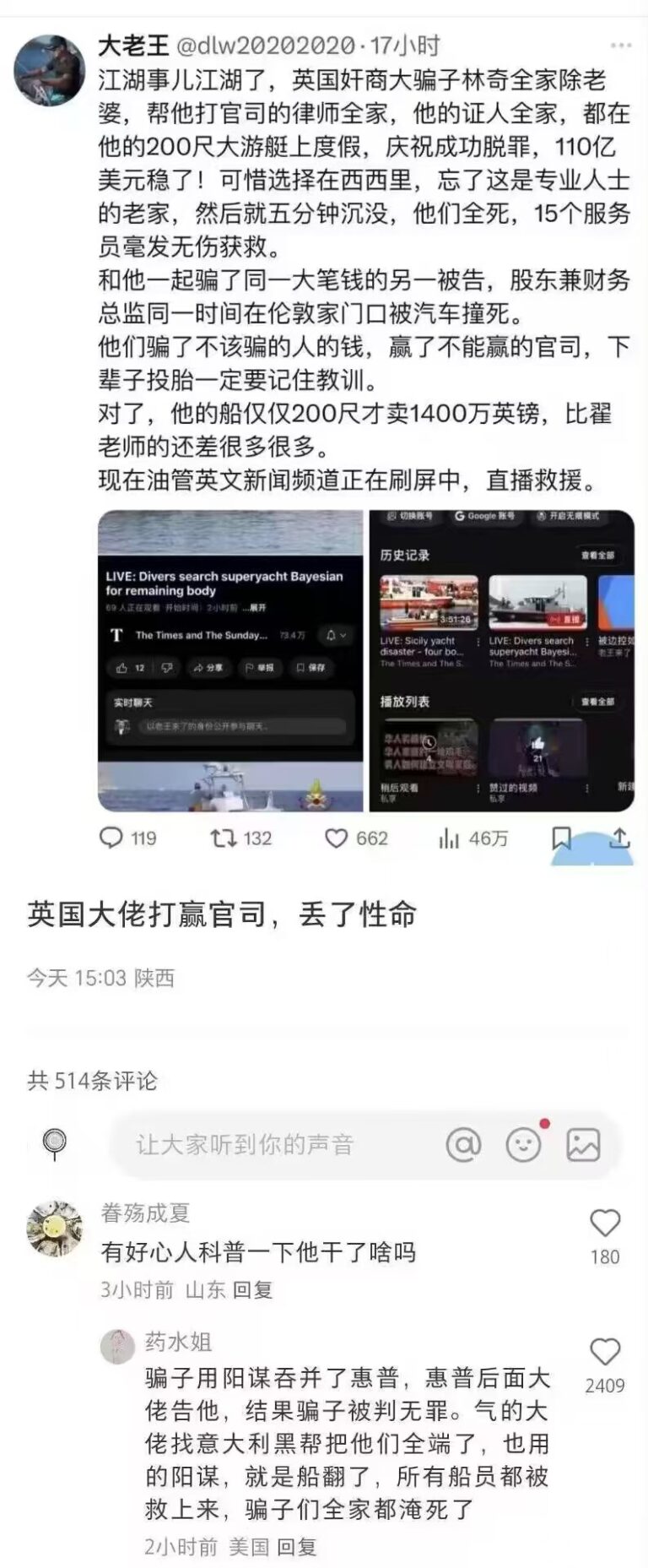
在商业世界中,成功往往是金钱和权力的代…

在当今快速发展的人工智能领域,深度学习…

在人工智能的浩瀚宇宙中,大语言模型如同…

非常简单的彻底解决方案: 控制面板->硬件…

引言 在机器学习的领域中,解耦表示学习旨…

🧙♂️ 想象一下, 你有一个魔法笔记本, 只要…

在计算机视觉和自然语言处理的交叉地带, 一…