代码预训练:提升语言模型实体追踪能力的新途径 2024-06-03 作者 C3P00 引言:语言模型的新突破 在人工智能领域,语言模型的能力一直在不断进化。最近,一项引人注目的研究表明,通过在代码 ... 阅读更多
100 开头的 IP 地址:是公网还是内网? 2024-06-03 作者 C3P00 你是否留意过自家路由器的 WAN 口 IP 地址?最近,越来越多的用户发现自己的 IP 地址是以 「100」 开头。这是否意味 ... 阅读更多
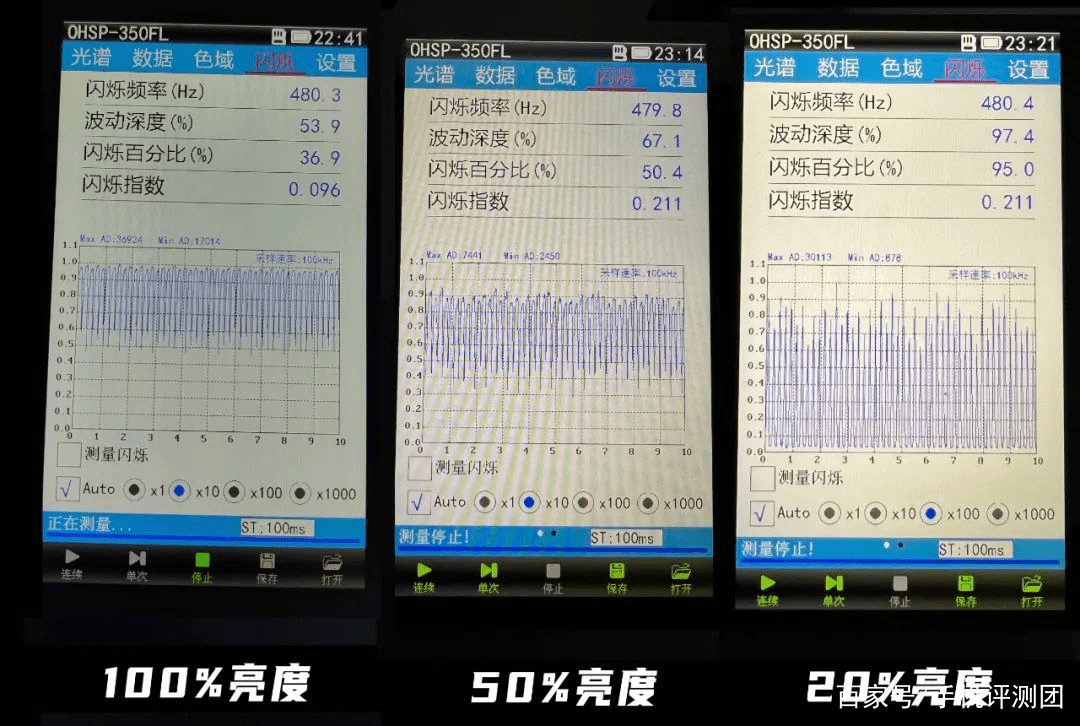
OLED 屏幕频闪:揭开真相的科普 2024-06-03 作者 C3P00 随着智能手机的普及和使用时间的增加,人们对于手机屏幕对眼睛的影响越来越关注。其中,OLED 屏幕频闪问题备受争议 ... 阅读更多
OLED 屏幕的频闪问题:真相揭秘 2024-06-03 作者 C3P00 随着智能手机的普及和使用时间的增加,人们对于手机屏幕对眼睛的影响越来越关注。其中,OLED 屏幕频闪问题备受争议 ... 阅读更多
SSE (Server-Sent Events) 概念和工作原理 2024-06-03 作者 C3P00 一、什么是 SSE? Server-Sent Events (SSE) 是一种服务器推送技术,允许服务器单向地 ... 阅读更多
苹果公司近期开发了一种名为 ReALM(Reference Resolution As Language Modeling) 的系统 2024-06-03 作者 C3P00 苹果公司最近在人工智能领域取得了新的研究进展,他们发布了一种名为 ReALM 的人工智能系统,该系统具有优于 GPT ... 阅读更多
UDP 打洞穿透 NAT:突破网络限制的利器 2024-06-03 作者 C3P00 在现代网络通信中,我们常常遇到一个问题:由于网络中存在防火墙和 NAT 设备,使得处于不同网络环境下的计算机难以直 ... 阅读更多
泡面帝国的衰落:方便面为何不再方便? 2024-06-03 作者 C3P00 曾经,泡面是无数人心中的 「深夜食堂」,是学生时代的美味记忆,也是旅途中的便捷伴侣。然而,近年来,方便面市场却逐 ... 阅读更多
方便面销售下滑:原因解析与趋势展望 2024-06-03 作者 C3P00 方便面作为一种快捷、方便的食品,在过去几十年中一直备受消费者的喜爱。然而,近年来,人们注意到三大方便面巨头的销 ... 阅读更多